This is the multi-page printable view of this section. Click here to print.
Concepts
1 - What is 2DFS?
![]() 2DFS is a two-dimensional filesystem build and distribution framework for containers.
2DFS is a two-dimensional filesystem build and distribution framework for containers.
What is 2DFS?
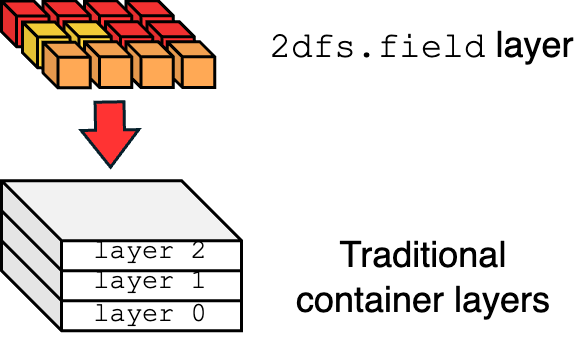
An extension of the container layered structure with a new two-dimensional filesystem layer type, specifically designed for efficient handling of large data.
2DFS is composed of:
- A new container layer type:
2dfs.field - A 2DFS builder, to build a
2dfs.fieldon top of a regular OCI container image - A 2DFS Registry, to host and distribute
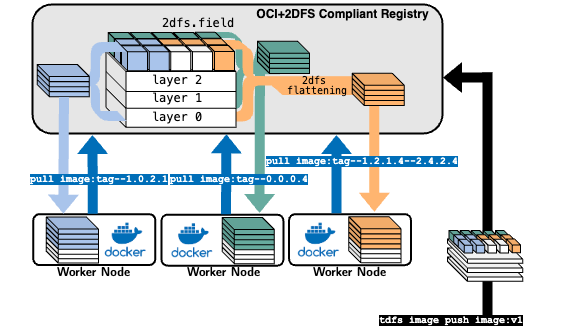
2dfsand OCI compliant images. - A 2DFS flattening technique, allowing 2DFS images to be pertitioned on demand and distributed as traditional OCI images for ANY runtime.
Features
- 2DFS Builder: A tool to build 2DFS images from OCI images, with a focus on large data handling. Build performance up to 50x faster than Docker for large data.
- 2DFS Registry: A registry to host and distribute 2DFS images. It allows image partitioning via semantic tags, enabling on-demand retrieval of only the required data. This is particularly useful for large datasets, AI model partitions, drivers, and other large data files.
- 2DFS Flattening: A technique to flatten 2DFS images into OCI images, allowing them to be distributed as traditional OCI images for any runtime. This enables the use of 2DFS images in your pre-existing infrastructure, without the need for any changes.
- Image Partitioning via Semantic Tags: 2DFS images can be partitioned using semantic tags, allowing you to pull only the required data from the registry. This is particularly useful for large datasets, AI model partitions, drivers, and other large data files.
2 - The 2DFS container layer
2dfs.field is a new layer type that we place on top of a regular OCI container image.
The field is composed of allotments, each positioned in a specific row and column.
Definition
A field is a sparse hash-pointer matrix of allotments representing a self-contained, non-overlapping, and independent filesystem space.Each allotment can contain one or more files or, for instance, a split of a neural network, a binary file, a driver, or any other large data file.
Ok but why?
The two-dimensional shape improves build and cache performance by relaxing vertical dependencies across layer changes, and most importantly, it is a human-friendly way to organize the space. In fact, we can retrieve specific rows and columns of the field from a container image, allowing us to pull only the data we need, when we need it.Instead of creating a new container layer to place a file using the ADD primitive of the Dockerfile, we create a descriptor called 2dfs.json that places each file (or a set of files) into a row and a column of the field.
For example, this 2dfs.json descriptor file:
{
"allotments": [
{
"src": "./file1.txt",
"dst": "/file1.txt",
"row": 0,
"col": 0
},
{
"src": "./file2.txt",
"dst": "/file2.txt",
"row": 0,
"col": 1
},
{
"src": ["./file3.txt", "./file4.txt"],
"dst": ["/file3.txt", "/file4.txt"],
"row": 1,
"col": 0
},
{
"src": "./file5.txt",
"dst": "/file5.txt",
"row": 1,
"col": 1
},
{
"src": "./file6.txt",
"dst": "/file6.txt",
"row": 2,
"col": 1
}
]
}
Will create a field like this:
| Row/Col | Col 0 | Col 1 |
|---|---|---|
| Row 0 | file1.txt | file2.txt |
| Row 1 | file3.txt,file4.txt | file5.txt |
| Row 2 | file6.txt |
The benefits?
- If I update file1.txt, the cache will preserve all the other allotemtns, boosting the image build. No cache invalidation happening.
- If I want to retrieve only file1.txt, I can only pull column 0 of row 0, and I will get only that file.
- We can create partitions by drawing a rectangle on the field, and retrieve only the files we need. For example, if I want to retrieve file1.txt and file2.txt, I can pull the rectangle defined from row 0 and column 0 to row 0 and column 1, and I will get only those two files.
- Since the field is a sparse matrix, we can have empty rows and columns which don’t decrease the performance of the image build and retrieval, and don’t consume space in the image.
3 - Deep Dive into 2DFS
Read more about 2DFS
We published a paper at USENIX ATC 2025 that dives deep into the design and implementation of 2DFS.